
Over the last few weeks, I’ve been working on learning some basic reinforcement learning models. All my code is available here (warning: basically totally undocumented and uses code from a few sources. It’s not the prettiest).
The Environment
The environment I used was the OpenAI Gym. The Gym is a library created by OpenAI to use as a benchmark for reinforcement learning systems. For my first experiments, I used the CartPole environment:
The goal of this environment is to keep the pole balanced for as long as possible by moving the cart left and right. It has three actions– left, right, and no-op, and four inputs: position and velocity of the cart, and position and velocity of the pole.
Q-Learning

Q-learning update equation, from Wikipedia
The first model I implemented was a basic Q-Learning model. Q-learning operates by estimating the expected value of each action given the current state, including both the reward from the immediate next time step and the expected reward from the resulting state. For my implementation, the Q function is simply a matrix mapping (state, action) -> value, and at any time step it selects the action which has the highest value in the given state, with some small probability of choosing randomly instead (this helps it explore and makes it less likely to get trapped in local minima.
And it learns! Quite quickly, in fact.

A graph showing progress of a Q learning model (x-axis is training iteration, y-axis is how many frames it survived)
This is comparatively simple to implement, but has some problems. Specifically, the state space must be discrete. In order to make it possible to index into this matrix with (state, action) pairs, the state space has to be discrete, In order to do this I binned the parameters provided by the environment (8 bins for each of the cart parameters, 10 bins for each of the pole’s parameters, which is 6400 possible states). There’s a trade-off here, since more states results in a finer-grained model which is better able to comprehend the state of the environment, but takes longer to train because there are more spaces to fill in the matrix, and each one will be encountered less frequently (the state space becomes sparser).
How do we solve this problem? We need to go deeper.
Deep-Q
The only difference between basic Q-Learning and Deep-Q Learning is that the Q function is a neural network instead of a matrix. This allows us to use a continuous state space. The network is trained to produce the same value used above for the more basic Q-Learning model. This model should perform better in theory, because of this.
Unfortunately, this model wasn’t very practical. The Q function estimates the value of each action separately, which means that the model runs several times per iteration. This makes it very slow to train, which makes it kind of miserable to iterate. It was learning, but so slowly, I moved right on to my next experiment for the sake of time and my sanity.
Asynchronous Actor-Critic
The Actor-Critic model improves over Q-learning in two significant ways. First off, it’s asynchronous. Rather than having a single network, it parallelizes the learning across multiple workers which each have their own environment. Each workers’ experiences are used to update the shared network asynchronously, which results in a dramatic improvement in training performance.
Secondly, it doesn’t just output the value (V(s), below), which corresponds to the value of the current state (similar to the Q value above, but it doesn’t consider actions), it also outputs the policy (π(s) below), which is a distribution over all possible actions. Importantly, the network’s own value judgements are used to train its policy- based on the action taken, it compares the value of the new state and updates the policy with respect to the previous state to reflect that.
We can make one more improvement: Instead of using the value estimations and rewards directly, we can calculate the advantage. This represents how much higher the reward was than estimated, which gives a larger weight to places where the network struggles and lets it exploit sparse rewards more effectively.

A diagram of the Asynchronous Actor-Critic model (from here)
I used a different environment than before, moving out of the parameterized space into a more complex environment: Breakout. It’s one of the atari

The Breakout environment
My specific architecture used 2 convolutional layers to parse the images, followed by a single LSTM layer to get time relations, and then a set of fully-connected layers for the policy and value outputs. You can see an early example of it above! This model actually worked very well for me– here’s the tensorboard output from 20 hours of training:
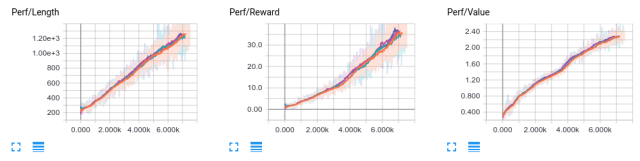
Graphs showing a steady increase in length, reward, and value
Interestingly, the gradient and variable norm also increased over the course of the training, which suggests that I need to normalize the model more strongly, but given the duration of the test, I’m not sure I want to cross-validate that.
Unfortunately, due to an error which would very rarely not terminate a training episode, the workers all died at the end and my computer ran out of memory as the episodes dragged on forever (alas). However, it did still seem to be improving when it died, and I still have the model, so I plan to continue training and see just how good it eventually gets. I also made a few improvements over that first try above, which you can see in the sample below:

A black-and-white, cropped version of Breakout
As you can probably see, the images have been pre-processed to crop out the score, resized, and converted to black-and-white for efficiency. Additionally, I moved the training and sampling of the network run on my GPU, which freed up the CPU to run the simulations of the environment. This more than doubled the speed of the training and was what made it reasonable to train overnight like I did above.
Option-Critic
One feature of the Atari environments caught my attention, though: Frame skip. In the Breakout environment, each action has a random chance of being repeated 2, 3, or 4 times, which adds some noise to the behavior of the agents that they have to account for. I began to wonder, however, how an agent might perform that was able to choose how many frames to execute an action for. It’s been done before with a Q-learning model, but this model simply adds an additional version of each decision that corresponds to each number of time steps, which dramatically increases the cost of choosing an action and the number of hyperparameters, and makes the model more sparse in general. What would be ideal is a model which can use some sort of regression to select. Fortuitously, the Actor-Critic model is ideal for this!
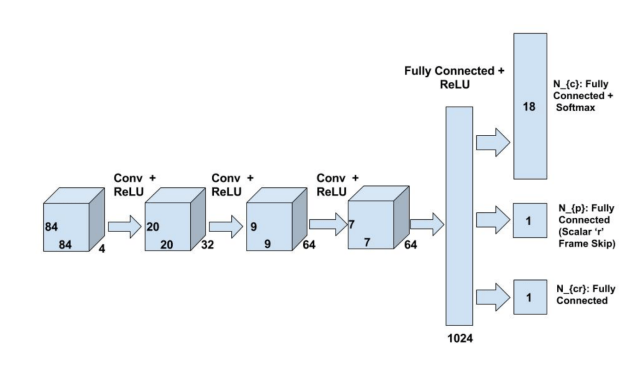
The architecture proposed by Lakshminarayanan et. al. in the paper above
We can simply add another output to the model which selects the number of times to repeat the chosen action.
This is remarkably similar to a concept called “options.” Options generalize decisions over time by outputting not a single discrete decision, but two components: a distribution over possible actions (we have that already), and a termination condition. Ideally, the termination condition would be some subset of the possible states, such that the option could continue until some state is reached, however this is difficult to accomplish with the neural network interpreting the states. Instead, our termination condition is a simple scalar which will sample from that distribution the given number of times.
This is what I’ve been working on, but unfortunately, learning the options seems to be much more difficult than learning one-frame actions. My best results have come from bootstrapping the network with the pre-trained checkpoint from the actor-critic model above, but it simply always chose a duration of 1 frame and then continued learning exactly as before. If I choose to reward the model for using larger time steps, it always chooses the maximum and ignores the ball completely to cash in on that easy reward. Reward engineering is tough!
In the near future, I’ll continue working on this problem and see what I can make of it, but unfortunately with this sort of reinforcement learning model, sometimes it’s nigh-impossible to identify the source of a bug, and iteration takes so long that it’s difficult to find them all in a reasonable amount of time.
Next steps
My next step in this is really to move out of the OpenAI gym and out into the wild a little bit, or rather, into unity. Unity is a very popular game development engine which recently released a toolkit for training machine learning agents in environments created in the engine. This opens up some really interesting possibilities, as the environments can be anything you can create in unity, including physics and collision simulations, realistic lighting, and, most importantly, human interaction. This opens up a lot of really interesting possibilities that I’m excited to explore.

